Apache Hadoop
Apache Hadoop은 분산환경에서 빅데이터를 저장하고 처리할 수 있는 Java기반의 오픈소스 프레임워크입니다. Hadoop은 파일 시스템인 HDFS와 데이터를 처리하는 MapReduce 엔진을 합한 것을 말합니다.
Hadoop은 job을 여러 노드로 분산하고, 전체연산을 잘게 나눠 병렬처리가 가능하게 하였으며, 부분적으로 장애가 발생하여도 문제없이 동작하는 장애 내성을 갖는 시스템입니다.
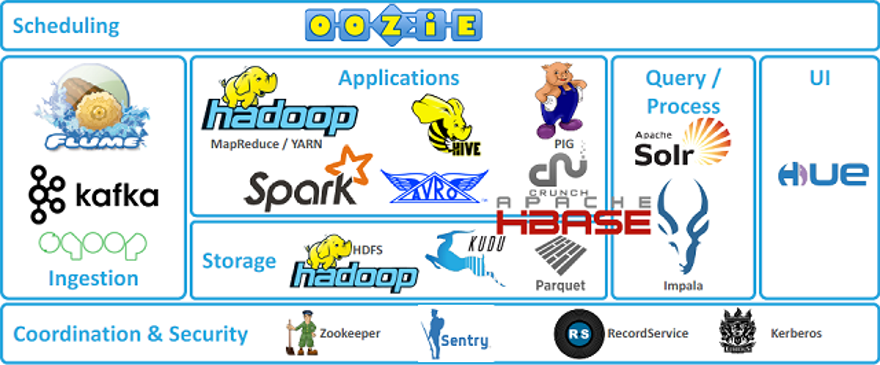
Hadoop의 코어 프로젝트는 HDFS와 맵리듀스이지만 그 외에도 다양한 서브 프로젝트가 존재합니다. 하둡의 코어 프로젝트와 이를 구성하고 있는 다양한 서브 프로젝트를 모아 놓은 것을 하둡 에코 시스템이라고 합니다.
Haddop Ecosystem의 다른 프로젝트들은 Hadoop을 완전히 대체한다고 하기 보다는 Hadoop 시스템과 같이 사용하여 부족한 기능을 보완하고, 서로 시너지를 낸다고 할 수 있습니다.
Haddop Ecosystem
Core Project + Sub Project
- 비정형데이터 수집 : 플럼
- 메시지 큐 : 카프카
- 데이터 처리 : 스파크, 피그, 하이브
- 워크플로우 관리 : 우지
- 데이터 직렬화 : Avro
- 데이터 저장소 : HBase, kudu
- 분산 환경 코디네이터 : Zookeeper
- 실시간 SQL 질의 : Impala
- 웹 인터페이스 제공 : hue
HDFS(Hadoop Distributed File System)
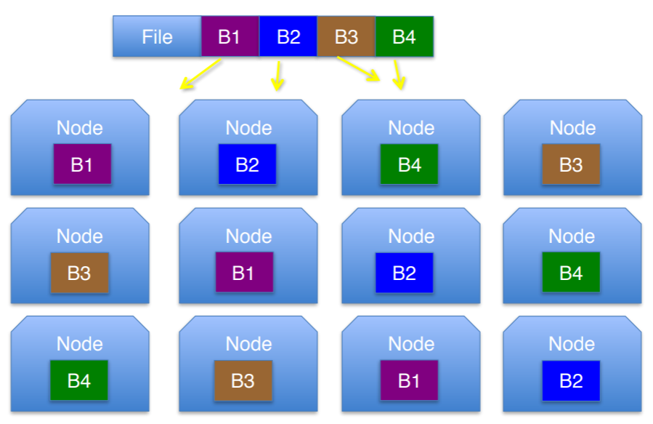
HDFS는 수백 기가, 테라 단위의 대용량 파일을 블록 단위로 쪼개어 분산된 서버에 저장하고, 많은 클라이언트가 저장된 파일을 빠르게 처리할 수 있도록 지원해주는 파일 시스템입니다.
데이터 블록들을 여러 서버에 쪼개어 중복 저장하기 때문에 하나의 노드(서버)에서 장애가 발생하더라도 이상이 없는 장애 내성을 갖게 됩니다.
HDFS는 큰파일을 저장할 때 유리하고, 작고 많은 파일이나 낮은 latency가 필요한 파일에는 적합하지 않습니다
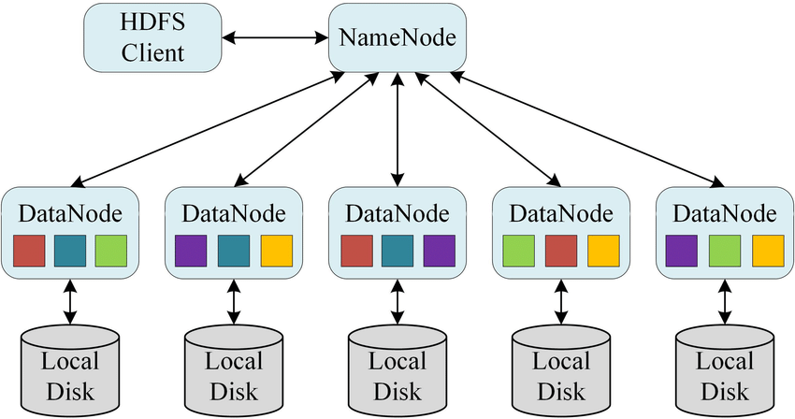
HDFS는 네임노드와 데이터노드로 구성됩니다.
네임노드는 클라이언트의 요청을 접수하고, 메타 데이터를 관리하며, 데이터노드를 모니터링하는 역할을 수행합니다.
데이터노드는 클라이언트가 HDFS에 저장하는 파일을 로컬 디스크에 유지하는 역할을 담당합니다.
MapReduce
MapReduce는 분산 컴퓨팅을 위한 프레임워크를 말합니다.
하둡은 MapReduce라는 단순한 데이터 처리 모델을 사용함으로써 여러 대의 컴퓨터를 통해 손쉽게 대규모 데이터를 처리합니다.
MapReduce는 인풋 데이터를 독립적인 블록으로 나누고 이를 병렬적으로 처리합니다
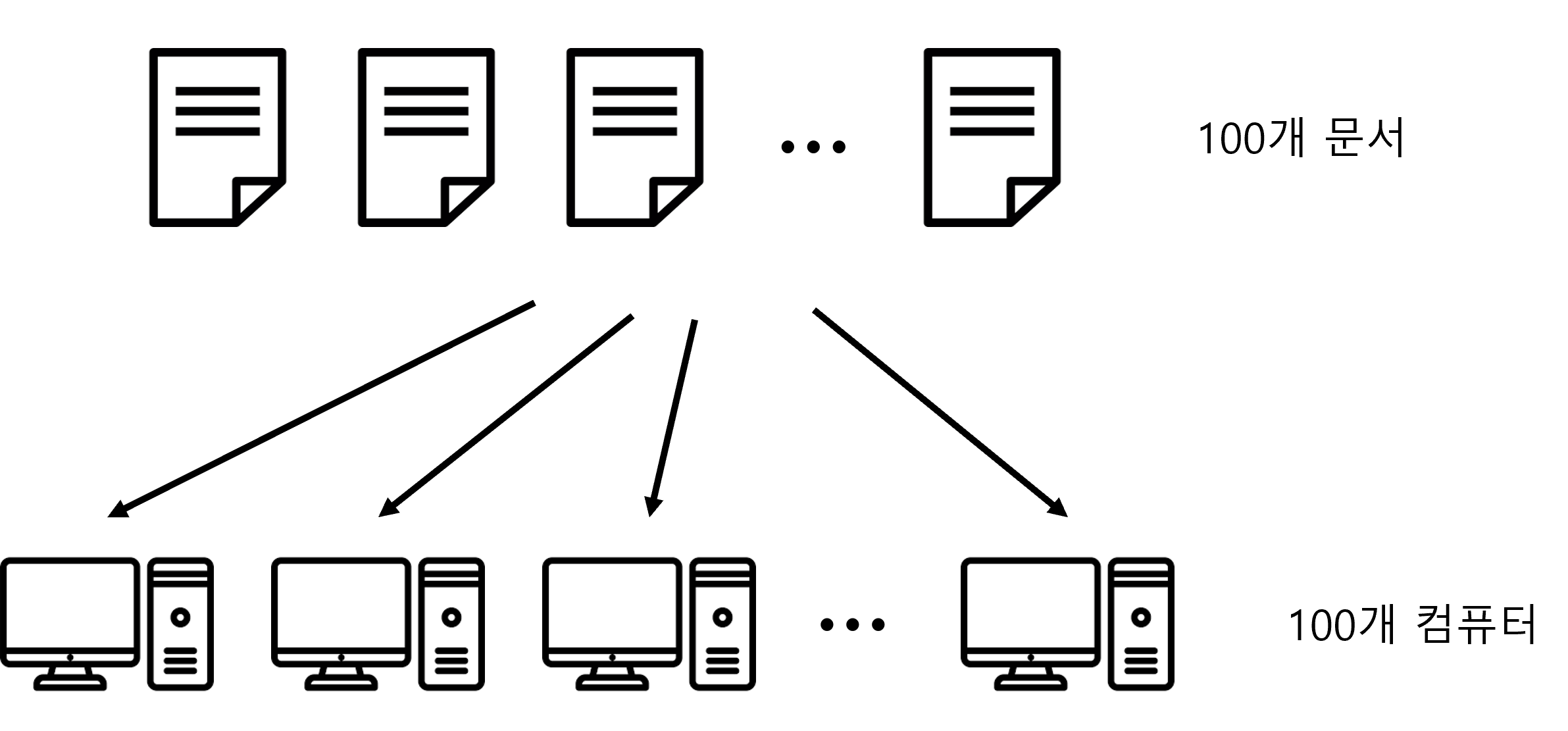
예를들어 100개의 문서가 있고 그 문서들에서 단어의 빈도수를 추출하여 하나의 파일로 만드는 프로그램을 만든다고 가정해봅니다.
쉽게 생각하면 100개의 문서를 100개의 컴퓨터에 하나씩 할당하고 이를 처리한 후 결과를 취합하는 식으로 생각할 수 있습니다.
하지만 이때 고려해야할 사항이 여러개 존재합니다.
- 100개의 컴퓨터 중 한대가 고장났을 경우
- 100개의 문서 중 하나의 문서가 엄청 길어 다른 컴퓨터들이 기다려야하는 경우
- 100개의 처리결과가 컴퓨팅 자원 부족으로 하나로 합쳐지지 않을 경우
MapReduce는 이러한 상황을 모두 고려하여 분산 처리를 쉽게 할 수 있도록 지원해주는 프레임워크입니다.
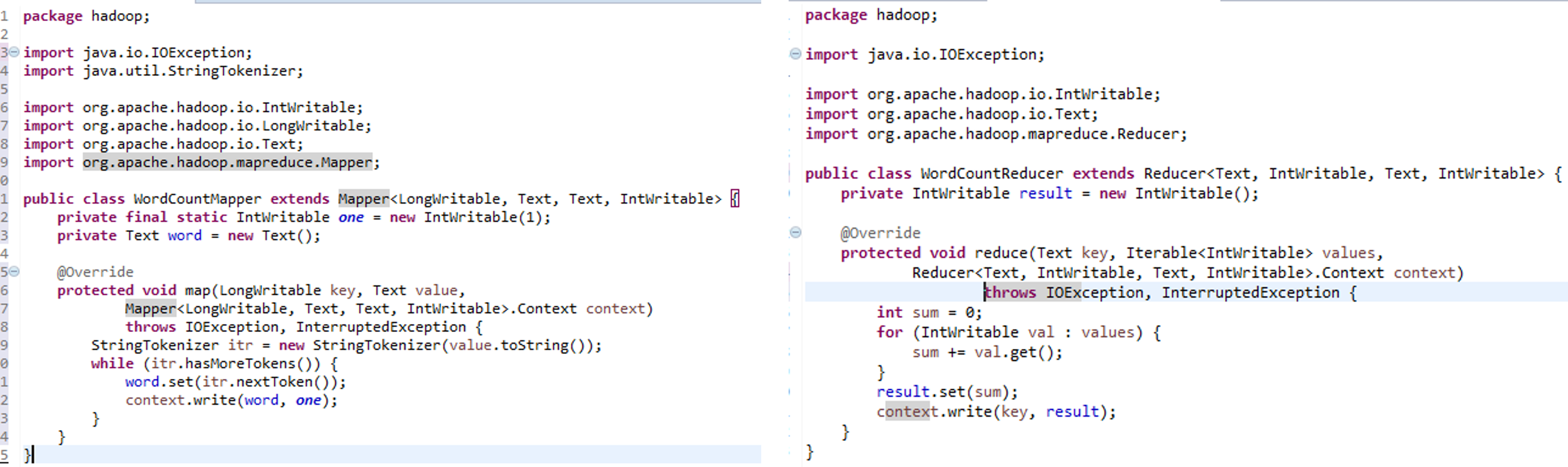
Java에서는 Mapper와 Reducer라는 class를 상속한 후 함수들을 Overriding하여 필요한 기능을 구현합니다. 이후 driver라는 메인클래스에서 실행합니다.
MapReduce는는 최소한 API만 노출하여 대규모 분산 시스템을 다루는 복잡한 작업을 감추고, 병렬처리를 프로그래밍 방법으로 할 수 있도록 지원합니다.
MapReduce는 Map과 Reduce 두가지 페이즈로 나뉩니다.
Map은 입력 데이터를 스플릿 단위로 나뉘어 각 노드에 할당하고, key-value 형식으로 변환시킵니다.
Reduce는 map의 출력데이터를 사용자가 정의한 방법으로 합치어 key에 대한 정보를 추출합니다
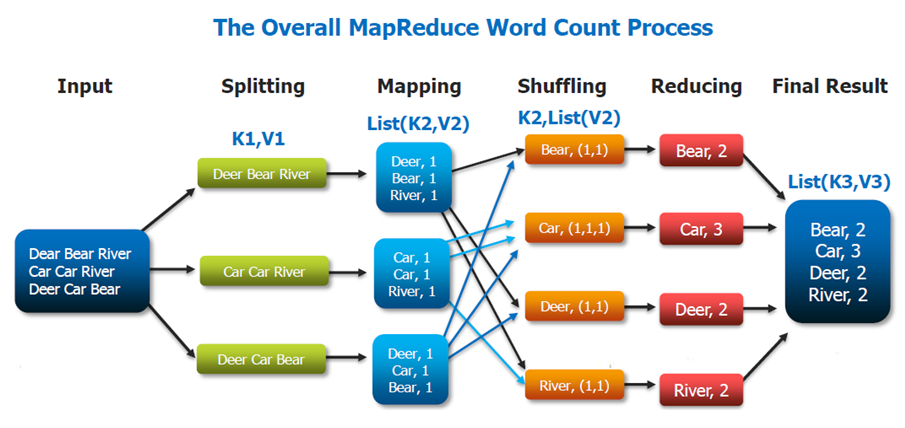
아래는 WordCount 예제입니다.
- splitting : 문자열 데이터를 독립적인 단위로 나누어 노드에 할당
- mapping : 입력 데이터를 key-value 형태로 변환
- shuffling : 같은 key를 가지는 데이터끼리 분류
- reducing : 각 key별 빈도수를 합산하여 출력
- final result : 최종 결과는 hdfs파일로 저장