Apache Spark
Apache Spark는 오픈 소스 클러스터 컴퓨팅 프레임워크이며, 클러스터 환경에서 데이터 병렬처리를 지원합니다.
UC 버클리의 AMPLab에서 2009년 시작되었고 아파치 소프트웨어 재단에 기부되었습니다. 기본적으로 하둡의 MapReduce보다 10~100배 빠르게 설계가 되었습니다. 또한, job에서 필요한 데이터를 매번 디스크에서 가져오는 대신에 메모리에 저장하는 In-Memory 방식을 사용합니다. High level API를 제공하며 Java, Scala, Python, R에서도 사용가능합니다.

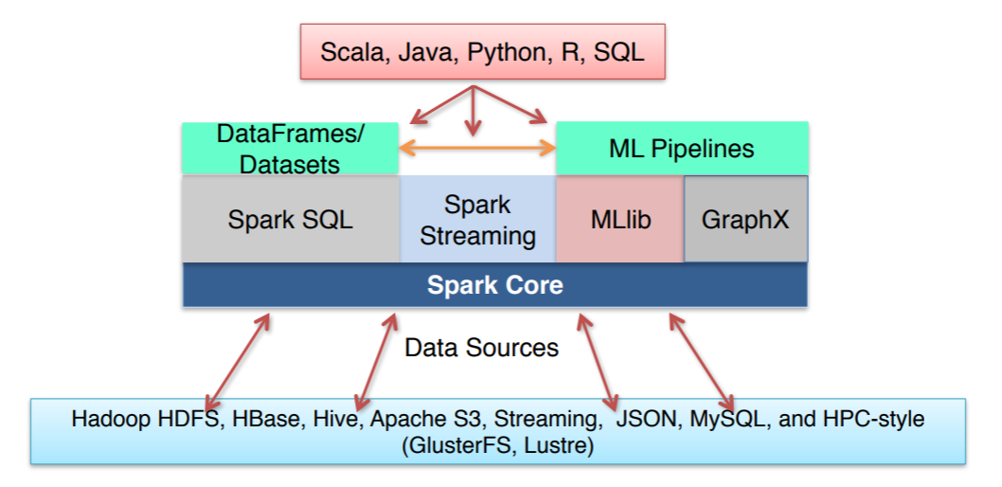
Apache Spark는 HDFS, HBase, json, mysql 등 소스에서 데이터를 가져올 수 있습니다.
또한, 널리쓰이는 네가지 언어를 지원하며, SQL 뿐만 아니라, 스트리밍, 머신러닝에 이르는 넓은 범위의 라이브러리를 제공합니다.
Apache Spark는 SQL과 구조화된 데이터를 제공하는 Apache Spark SQL, 스트림 처리 기능을 제공하는 Apache Spark 스트리밍, 머신러닝을 지원하는 MLlib, 구조적 스트리밍과 그래프 분석 엔진인 GraphX를 지원합니다.
Apache Spark는 단일 노트북 환경부터 수천대의 서버로 구성된 클러스터까지 다양한 환경에서 실행할 수 있습니다.
MapReduce VS Spark
Apache Spark는 하둡의 MapReduce와 주로 비교됩니다.
머신러닝, 딥러닝의 발전으로 데이터들을 반복적, 연속적을 처리해야하는 경우가 점점 늘어나게 되었습니다.
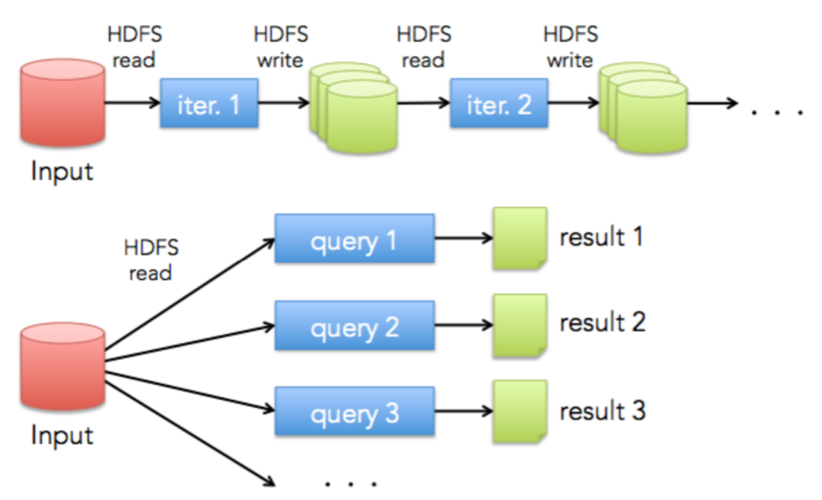
MapReduce에서는 job을 처리할때 hdfs에서 데이터를 읽고, 처리된 결과를 hdfs에 저장하게 됩니다. 또한, 연속적인 처리를 할때 이전 job의 결과를 이용하려면 이전 job을 hdfs에 저장한 후 다시 읽어야 합니다. 이렇게 읽고 쓰고를 반복적으로 하는 MapReduce의 방식은 매번 디스크, 네트워크 I/O가 발생하여 리소스가 낭비되게 됩니다.
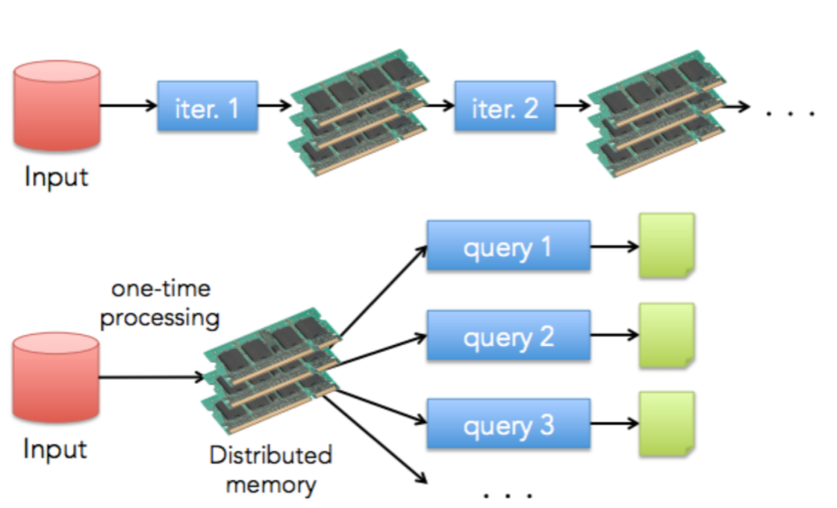
이와 반대로 Apache Spark는 저장된 데이터를 메모리로 불러온 후 변환과 계산을 거쳐 최종 산출물을 저장하게 됩니다.
Apache Spark는 인 메모리 프로세싱을 하기 때문에 디스크/ 네트워크 I/O가 매번 발생하는 하둡의 MapReduce보다 더 빠르게 수행될 수 있습니다.
쿼리 실행의 경우도 모든 데이터를 메모리에 띄운 다음 수행하기 때문에 더 빠릅니다.
MapReduce와 Apache Spark의 특징으로 서로의 용도가 다르다고 볼 수 있습니다.
MapReduce latency가 비교적 높아도 되는 배치 작업에 적합하며, Apache Spark는 latency가 낮은 스트림 데이터 처리에 적합합니다.
아래의 코드는 문자열 split 기능을 하는 프로그램을 하둡과 Apache Spark로 작성한 코드입니다.
하둡에서는 Mapper, Reducer라는 하둡라이브러리의 객체를 상속받아 메소드를 오버라이딩하고 최종적으로 구현된 클래스를 모아 jar형태로 만들어 배치형태로 하둡에 제출해야합니다.
반면에 Apache Spark의 경우 High level api를 제공하여 유저친화적이며, 더 간단하게 코드를 작성할 수 있습니다

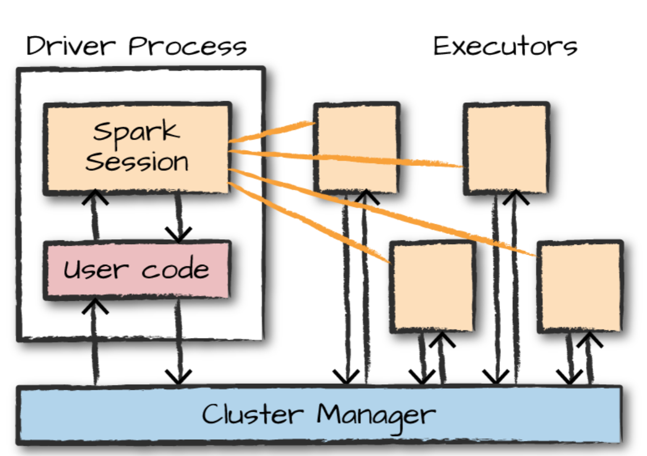
Spark Basic Architecture
Apache Spark 어플리케이션은 Driver Process와 다수의 Executor로 구성됩니다.
Driver Process는 Apache Spark 어플리케이션 정보의 유지관리, 사용자 프로그램에 대한 응답, Executor 프로세스의 작업지시, 배포 및 스케줄링을 담당합니다.
Executor는 Driver Process가 할당한 작업을 수행합니다
클러스터 매니저는 클러스터의 자원을 관리하고 처리중인 작업을 모니터링 합니다. Apache Spark에서는 클러스터 매니저로 Apache Spark Stand Alone, YARN, Mesos 등을 사용할 수 있습니다.
사용자는 유저코드를 작성하여 클러스터 매니저에 제출합니다. Apache Spark 어플리케이션(컴파일된 jar나 라이브러리)을 클러스터 매니저에 제출하는 것을 Spark- Submit이라고 합니다.
이와 동시에 클러스터 노드 중 하나에 Driver Process가 뜨게되고 클러스터 매니저에게 사용할 자원에 대해 요청하게 됩니다. 이후 Driver Process는 작업을 Executor에 할당하게 되고 Executor는 작업을 수행하게 됩니다.
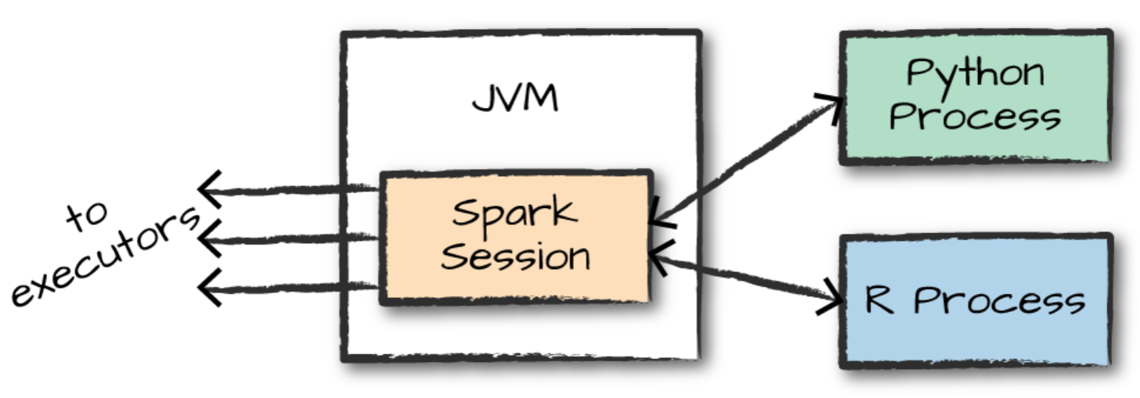
여기서 SparkSession은 Driver Process를 제어하고, 사용자가 정의한 코드를 실행하는 역할을 담당합니다.
Spark Language APIs
Apache Spark는 java, scala, python, R 언어를 지원합니다.
사용자는 Apache Spark를 실행하기 위해서 SparkSession을 진입점으로 사용합니다.
Apache Spark는 사용자를 대신하여 다른 언어로 작성된 코드를 Executor의 JVM에서 실행할 수 있는 코드로 변환합니다.
이와 같은 방법으로 다른 랭귀지들이 돌아갈 수 있는 인터페이스를 제공하게 됩니다.