
RDD(Resilient Distributed Dataset)
- RDD는 주된 Apache Spark 프로그래밍 추상화의 구조이며, 여러 노드에 흩어져 있으면서 병렬처리 될 수 이는 아이템들의 모임
- Apache Spark의 가장 기본적인 데이터 단위
- Resilient : 내결함성 및 장애시 데이터를 재구성할 수 있음
- 불변성(immutable) : RDD는 불변성을 가짐, 즉 한번 생성되면 변경할 수 없는 특징(Read Only)
- Distributed : Apache Spark 클러스터를 통하여, 메모리에 분산되어 저장됨
- Dataset : 값과 함께 파티션된 데이터 모음
- 파티션(Partition)
- 모든 익스큐터가 병렬로 작업을 수행할 수 있도록 파티션이라 불리는 청크 단위로 분할
- 파티션은 클러스터의 물리적 머신에 존재하는 로우의 집항르 의미
- RDD는 동일한 파티션을 여러 노드에 복제하여 고장내성을 가짐
RDD의 동작 원리
- RDD는 Apache Spark의 가장 기본적인 데이터 단위
- 모든 작업은 새로운 RDD를 생성하거나_이미 존재하는 RDD를 새로운 RDD로 변형하거나_최종 결과 계산을 위해 RDD가 연산 API를 호출하는 것 중 하나에 의해 수행됨
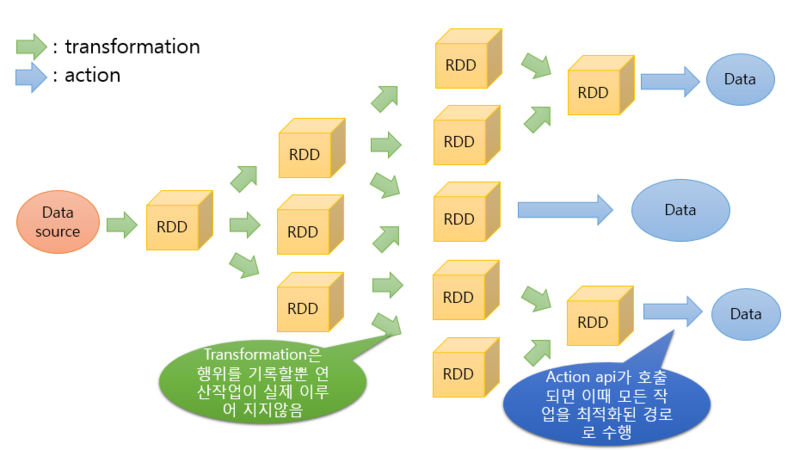
- Apache Spark에서 데이터 연산은 Transformation과 Action이라는 두가지 연산자을 통해 이루어짐
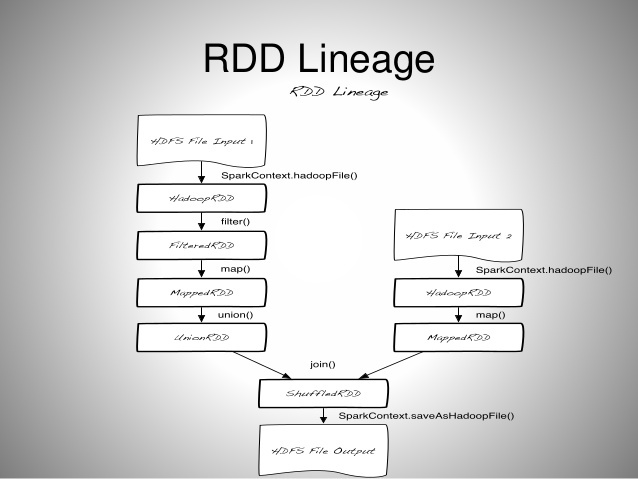
RDD Lineage
- RDD를 변경하는 순서를 Lineage라고 하며
- Lineage는 DAG(Directed Acycxlic Graph)형태를 가짐
- RDD 연산 과정에서 특정 RDD 관련 정보가 메모리에서 유실됐을 경우, DAG 그래프를 복기하여 다시 계산하고, 복구할 수 있음
- 이러한 특성 때문에 Fault-tolerant를 잘 보장함
Transformation
- 기존의 RDD에서 새로운 RDD를 생성하는 동작
- 좁은 의존성(narrow dependency), 넓은 의존성(wide dependency)를 가짐
- 좁은 의존성 : 가진 Transformation은 각 입력 파티션이 하나의 출력 파티션에만 영향을 미침
- 넓은 의존성 : 가진 Transformation은 하나의 입력 파티션이 여러 출렵 파티션에 영향을 미침
Action
- RDD 값을 기반으로 계산하여 결과를 생성하는 동작
- 사용자는 Transformation을 사용해 논리적 실행 계획을 세울 수 있음
- 하지만 실제 연산을 수행하려면 Action명령을 내려야함
지연연산(Layze Evaluation)
- 연산 그래프를 처리 직전까지 기다리는 동작방식, 쉽게 말해 즉시 실행하지 않는 것
- Action 연산자를 만나 전까지는, Transformation 연산자가 아무리 쌓여도 처리하지 않음
- Apache Spark는 특정 연산이 내려진 즉시 데이터를 수정하지않고 원시 데이터에 적용한 트렌스포메이션의 실행 계획을 생성
- 코드를 실행하는 마지막 순간까지 대기하다가 원형 DataFrame을 간결한 물리적 실행계획으로 컴파일
RDD VS DataFrames VS Datasets
RDD
- Release : 1.0
- Spark 등장 이래 주로 사용된 API
- Spark Core에서는 RDD는 변경할 수 없는(Imutable) 데이터의 집합으로 클러스터 내의 여러 노드에 분산되어 있음
- 언제 사용할까?
- low-level API인 Transformation, Action을 사용할 때
- 데이터가 미디어와 같이 비구조화형태로 되어 있을 때
- 데이터를 함수형 프로그래밍으로 조작하고 싶을때
- 데이터를 처리할 때, 컬럼 형식과 같은. 스키마를 굳이 따지고 싶지 않을 때
- 최적화를 굳이 신경쓰지 않을 때
DataFrames
- Release : 1.3
- RDD와 같이 Dataframes도 변경할 수 없는 데이터 집합
- 다만, RDB의 관계형 테이블처럼 컬럼이 존재, 따라서 대용량 데이터를 좀 더 쉽게 처리할 수 있음
- 또한 구조화 되어 있기 때문에 여러 데이터 엔지니어들이 쉽게 Spark에 접근할 수 있음
- 그러나 Spark 2.0에서 Dataframe API는 Datasets API와 통합됨
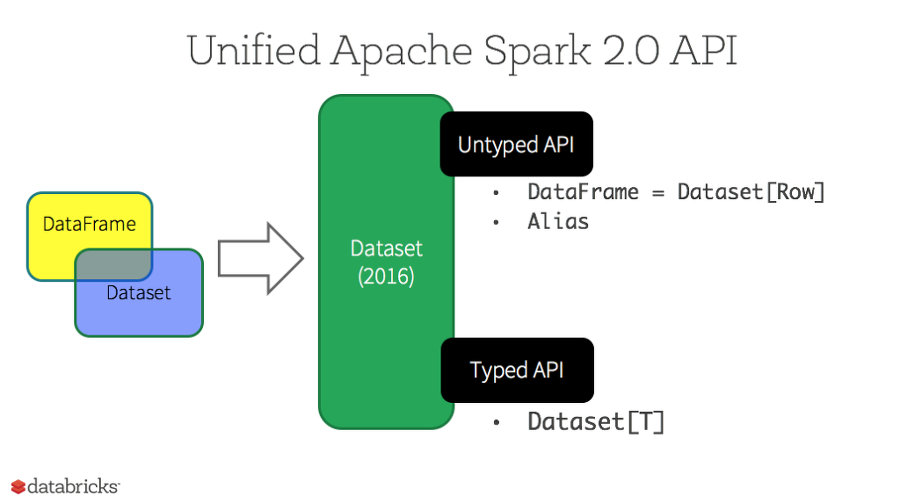
Datasets
- Release : 1.6
- Spark 2.0이 대두되면서, Datasets은 2가지 특징(strongly-typed API, uptyped API)를 가지게 되었다. 개념적으로 Dataframe은 제너릭(generic) 객체인 Dataset[Row]의 집합이며 Alias이다. (DataFrame = Dataset[Row])
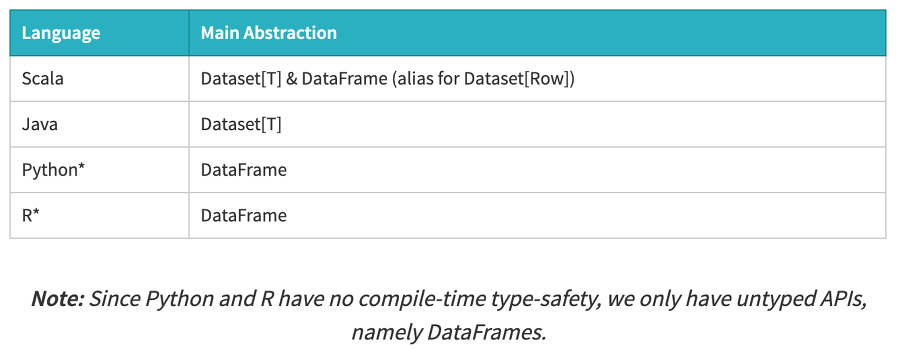
- Static-tying & runtime type-safety
- Spark SQL을 사용하면 실행할 때까지 문법 에러를 알 수 없다
- 반면에 Dataframe과 Dataset은 컴파일 시점에 에러를 잡을 수 있다
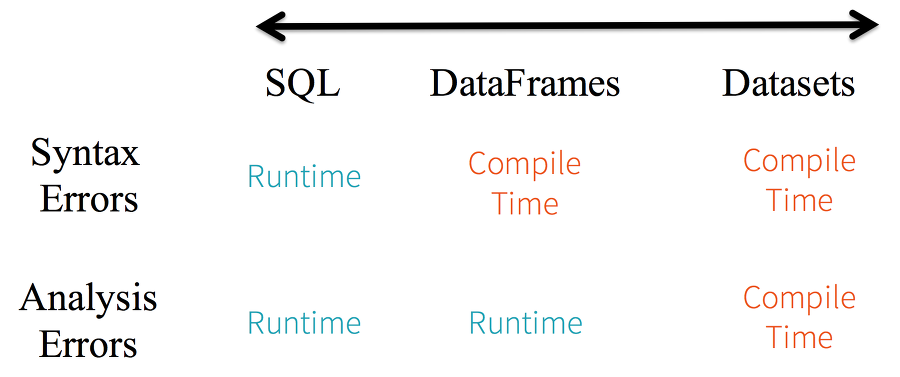
- High-level abstraction and custom view into structured and semi-structured data
- 예시) IoT json 데이터에 대한 dataset 생성
- json은 반구조화 형태이지만 Datasets[DeviceIoTData]와 같은 strongly tpyed의 집합으로 구성됨
- json 데이터 -> 추출하기 위한 클래스 -> json 데이터를 읽어서 클래스 형태 구성
- 타입이 명시된 데이터 집합인 Dataset으로 컴파일 시점에서 데이터 뷰를 확인할 수 있음
- 또한, Dataset[T] 형태는 High-level 메소드로 쉽게 작업 할 수 있음
- 예시) IoT json 데이터에 대한 dataset 생성
- Ease-of-use of APIs with structure
- 구조적 형태는 Spark에서 데이터를 다루는데 한계가 있을 수도 있음
- 그러나 Dataset은 쉽게 이해할 수 있고, 데이터를 다양하게 표현할 수 있음
- Performance & Optimization
- Dataframe과 Dataset은 Spark SQL 엔진 위에 탑재됨
- 즉, 최적화된 논리적 및 물리적 쿼리 계획을 생성할 수 있는 Catalyst를 사용할 수 있음
- 그러므로 R, Java, Scala, PYthon과 같은 언어도 같은 장점을 취할 수 있음

언제사용할까? * 도메인 API, 추상화 등이 필요할 때 * filters, maps, aggregation, 반구조화 데이터에서 람다 함수 등이 필요할 때 * Catalyst 최적화 및 Tungsten 코드를 사용하고 싶을 때 * API를 단순화하여 사용하고 싶을 때 * R, Python 사용자
요약하자면 RDD는 저수준 기능 및 제어, Dataframe과 Dataset은 고수준 및 도메인 작업 그리고 최적화에 적합함
참조링크
- https://timewizhan.tistory.com/entry/Spark-RDD-vs-Dataframes-vs-Datasets
- https://artist-developer.tistory.com/17
- https://loustler.io/data_eng/spark-rdd-dataframe-and-dataset/