이 글은 NiFi를 활용하여 MySQL의 데이터를 연동하는 방법을 설명하는 글이다. 가져온 MySQL 데이터를 분할하여 JSON으로 변환하는 방법까지 다룰 예정이다. Database Extrat with NiFi의 글을 참고하였다.
MySQL 데이터 생성
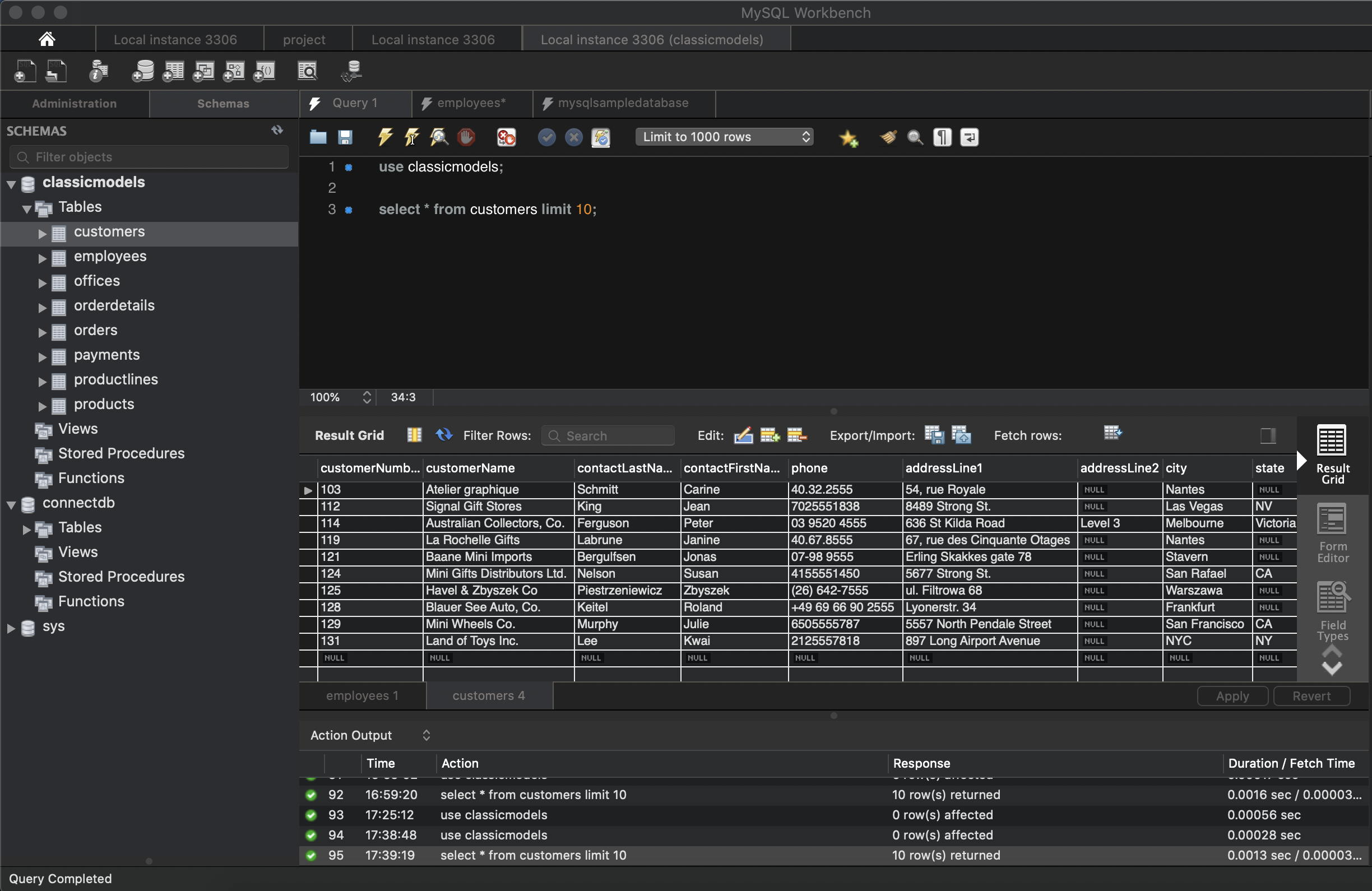
Sample 데이터의 경우 MySQL TURORIAL에서 제공하는 데이터를 이용했다. 파일을 다운 받은 후 압축을 해제하면 sql파일이 하나 있다. 해당 파일을 Workbench를 활용하여 실행시킨다.
File -> Open SQL Script… -> mysqlsampledatabase.sql
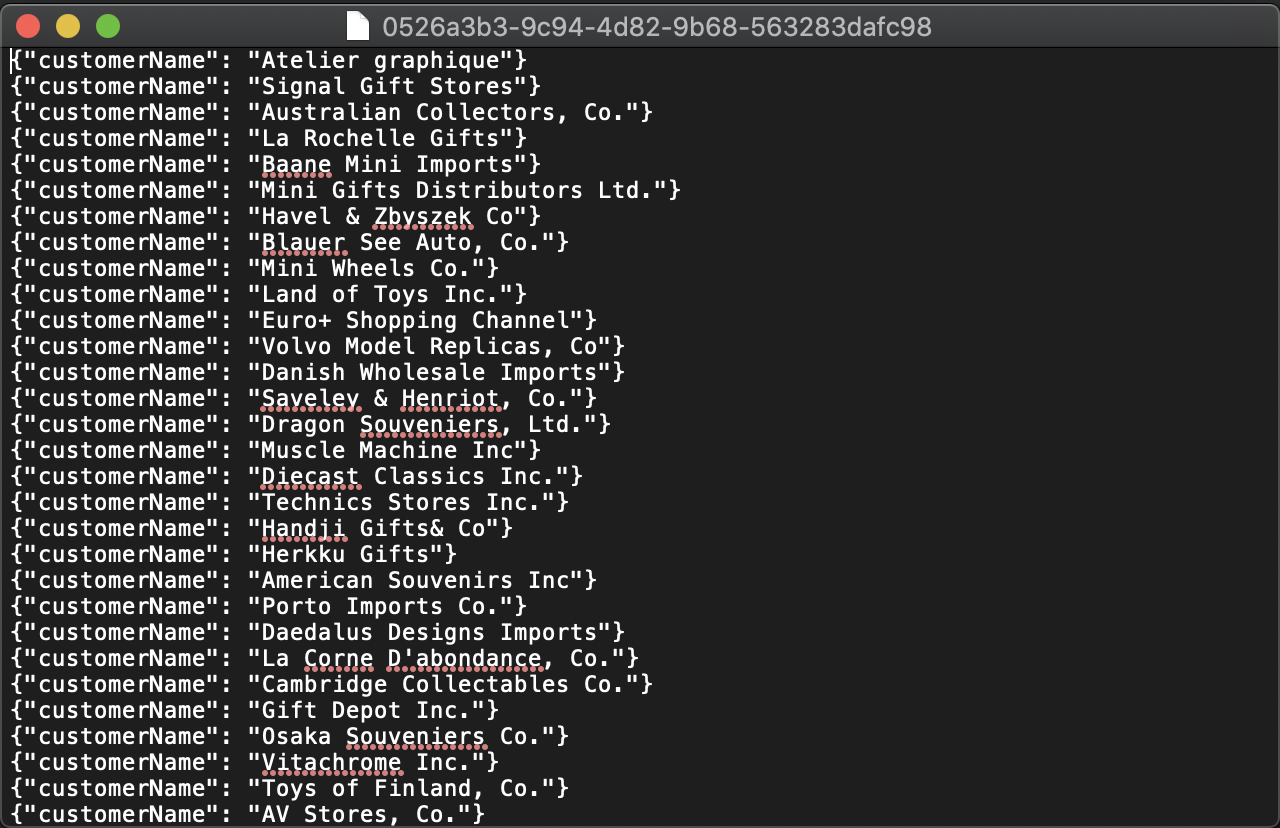
아래의 사진과 같이 데이터를 확인할 수 있다.
use classicmodels;
select * from customers limit 10;
Database 쿼리를 위한 Processor
NiFi에는 관계형 Database에서 행을 추출하기 위한 두 개의 Processor가 있으므로 필요에 맞는 것을 선택한다. 이번 예제에서는 QueryDatabaseTable을 사용한다.
- ExecuteSQL - 임의의 SQL문을 실행하고 모든 결과 레코드를 포함하는 Avro 형식의 하나의 FlowFile로 결과를 반환한다. 범용으로 설계되었으며, 증분되는 행에 대한 추출 기능이 없다.
- QueryDatabaseTable - 증분 추출을 위해 특별이 설계되었으며, 주어진 테이블 이름과 증가하는 열을 기반으로 SQL 쿼리를 만들어 준다. 검색된 마지막 증분 값을 추적하는 NiFi 상태 데이터를 유지하고, 결과는 Avro 형식의 FlowFile로 반환한다.
증분 추출하여 최신 레코드만 얻으려는 경우에는 QueryDatabasedTable을 사용할 것이다. SQL문을 개별 입력 FlowFile로 사용자 지정해야하는 경우 ExecuteSQL을 사용한다.
Avro File 설명
위에서 선택한 프로세서와 관계없이 쿼리 출력은 하나 이상의 레코드가 포함된 Avro FlowFile이 된다. Avro는 레코드 및 해당 스키마의 압축 저장을 위한 이진 직렬화된 형식의 파일이다. Avro 파일은 Haddop / Hive에서 수집하는 데 이상적이다. 그러나 항상 그런 것은 아니며 바이너리 형식의 Avro는 검사하고 작업하기 더 어려울 수 있다.
다행히, NiFi에는 Avro file을 처리하는 프로세서가 포함되어 있다.
- SpliAvro - 여러 레코드가 있는 Avro파일을 개별 Flowfile로 분할한다.
- ConvertAvroToJSON - Avro파일을 JSON으로 변환한다. 이는 JSON처리의 유연성과 JSON데이터를 시각적으로 쉽게 검사하는데 유용하다.
DBCPConnetionPool 설명
NiFi와 Database를 연동하게 된다면 사용하는 Controler Service 중 하나이다. Controller Service는 여러 프로세서에서 사용할 수 있는 shared service이다.
-
ConnectionPool
ConnectionPool이란 DB와 미리 연결 해놓은 객체를 pool에 저정해두었다가, 클라이언트의 요청이 오면 connection을 빌려부고, 볼일이 끝나면 다시 connection을 pool에 저장하는 방식을 말한다.
pool에 미리 connection을 생성해 놓기 때문에 connection을 생성하는 데 드는 시간이 없다. 또한, connection을 계속해서 재사용하기 때문에 생성되는 connection수가 많지 않다.
connection의 갯수는 한정적이기 때문에 동시 접속자가 많아져 connection이 모자랄 경우 반납될때까지 기다려야한다. 또한, connection 또한 객체이므로 메모리를 차지한다. 그렇기 때문에 유저 수에 따라 connection의 갯수를 조절할 필요가 있다.
Example - Extracting Database Rows to JSON Text
예를 들어, 데이터베이스의 일부 레코드를 한 줄에 하나의 JSON레코드가 포함된 텍스트 파일로 추출해 보겠다. 사용 중인 데이터베이스에서 증분된 내용만 추출하여 JSON으로 변환 후 다시 텍스트로 병합하여 저장할 것이다. JSON레코드는 텍스트로 병합하여 Hive와 같은 시스템에서 읽을 수 있기 떄문에 유용하다.
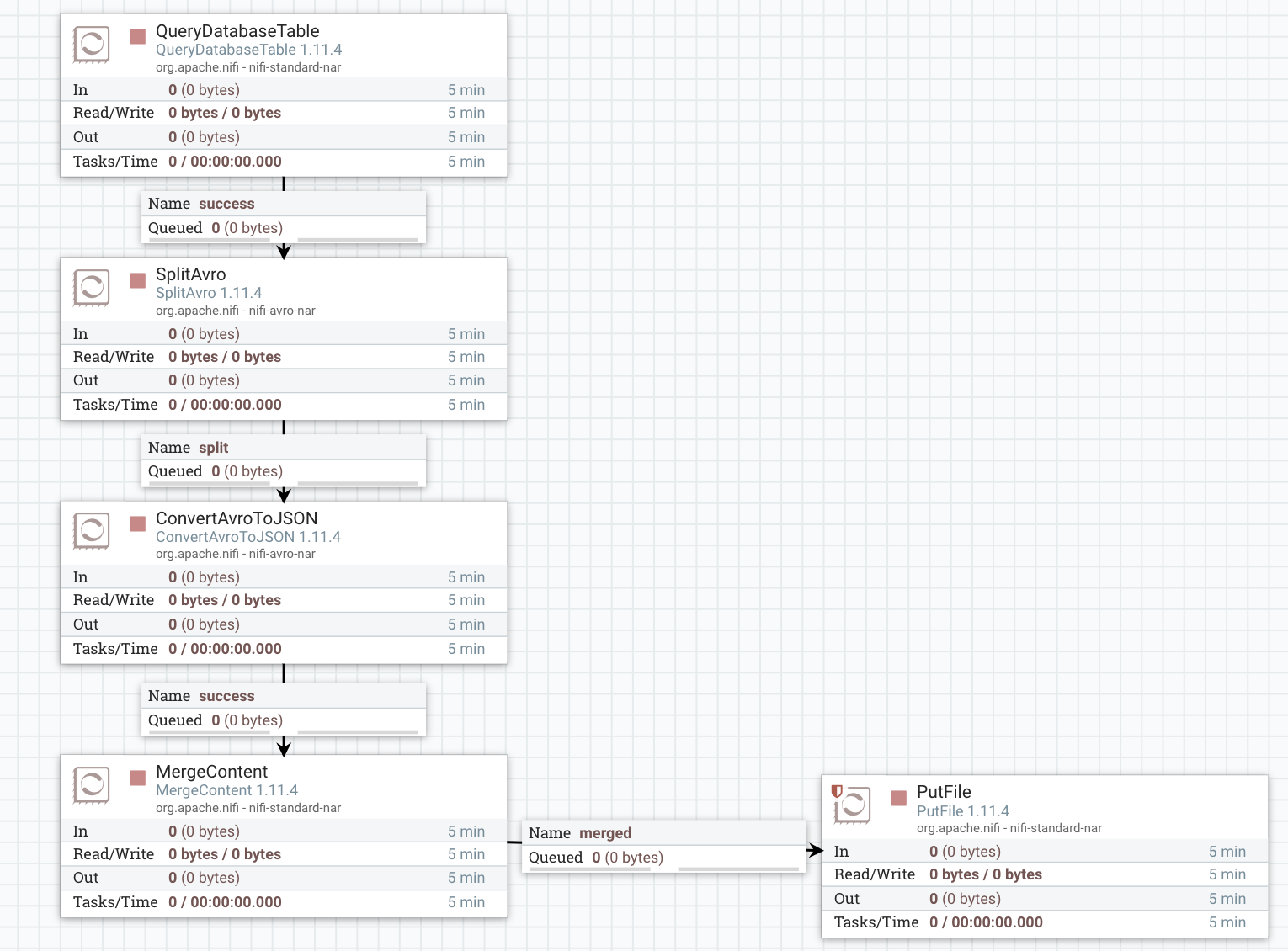
이번 sample에서는 다음과 같은 프로세서가 포함된다.
- QueryDatabaseTable - auto-incremented column을 사용하여 테이블의 레코드를 쿼리해 지금까지 처리한 레코드를 추출
- SplitAvro - Avro파일을 각각 단일 레코드로 분할
- ConvertAvroToJSON - Avro 레코드를 배열이 아닌 개별 JSON 객체로 변환함
- MergeContent - JSON라인을 다시 파일로 그룹화
- PutFile - JSON파일을 로컬에 저장
프로세서 설명
QueryDatabaseTable
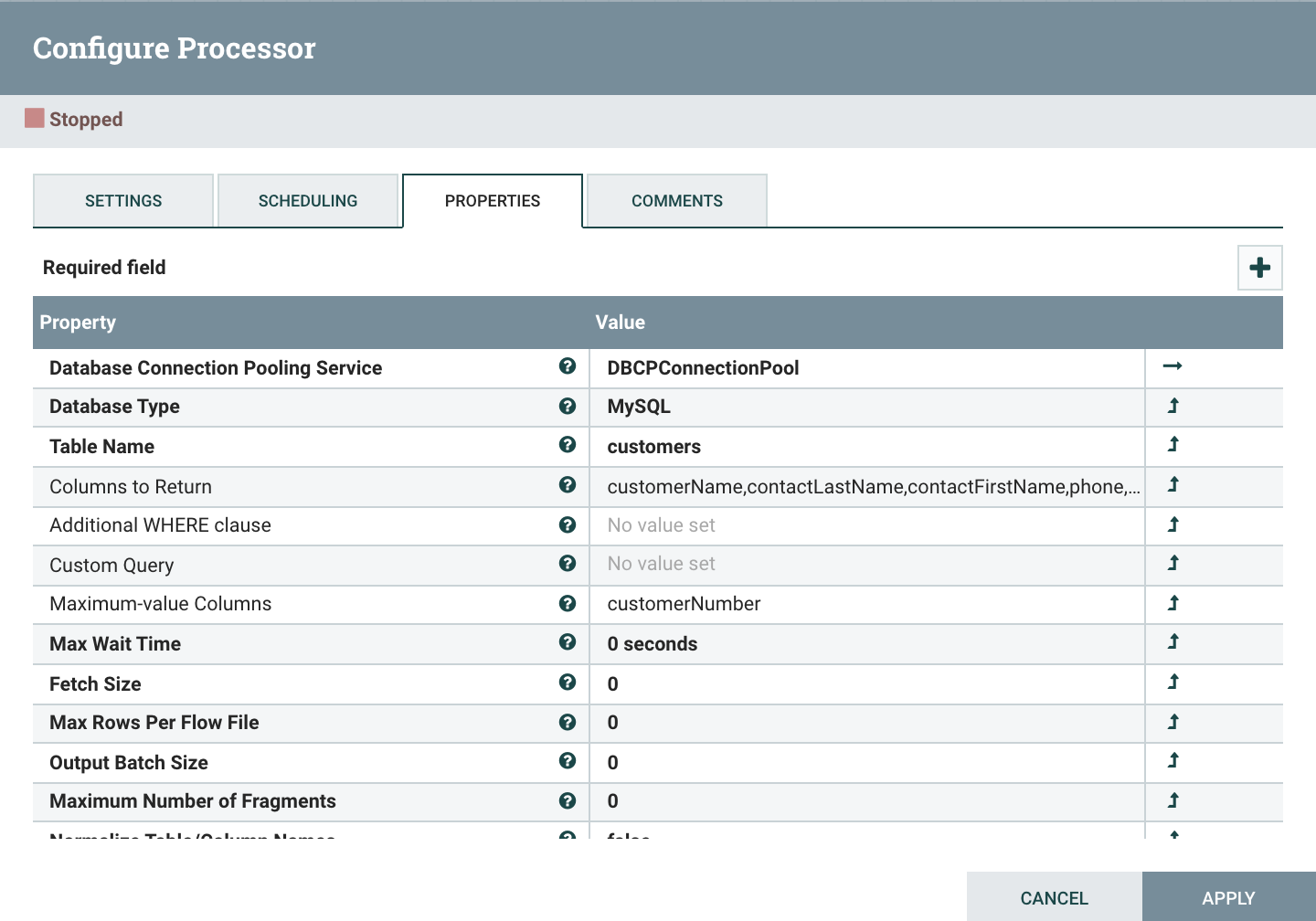
- Database Connection Pooling Service : 사용할 DB Connetction Pool을 설정한다. DB Connection Pool은 DB에 대한 접속정보를 입력하여 만들 수 있다. 오른쪽의 화살표를 클릭시 DBCPConnectionPool에 접근할 수 있다.
- Database Type : DB 타입을 지정한다. MySQL을 사용하므로 MySQL을 지정한다.
- Table Name : 정보를 가져올 DB의 테이블 이름을 입력한다.
- Columns to Return : 정보를 가져올 컬럼명을 콤마(,)로 구분하여 입력한다.
- Additional WHERE clause : Query문의 WHERE문에 해당하는 조건을 입력한다.
- Maximum-value Columns : 테이블에 값이 계속하여 증가하는 Sequence의 역할을 하는 컴럼을 지정하여 데이터를 가져올때마다 그 컬럼의 최대값을 가져온다. 다음 데이터를 가져올때 바로 전의 값과 비교하여 해당 값보다 큰 레코드만 가져올 수 있도록 한다.
DBCPConnectionPool
데이터베이스의 접속정보를 가지고 있는 Controller Service이다.
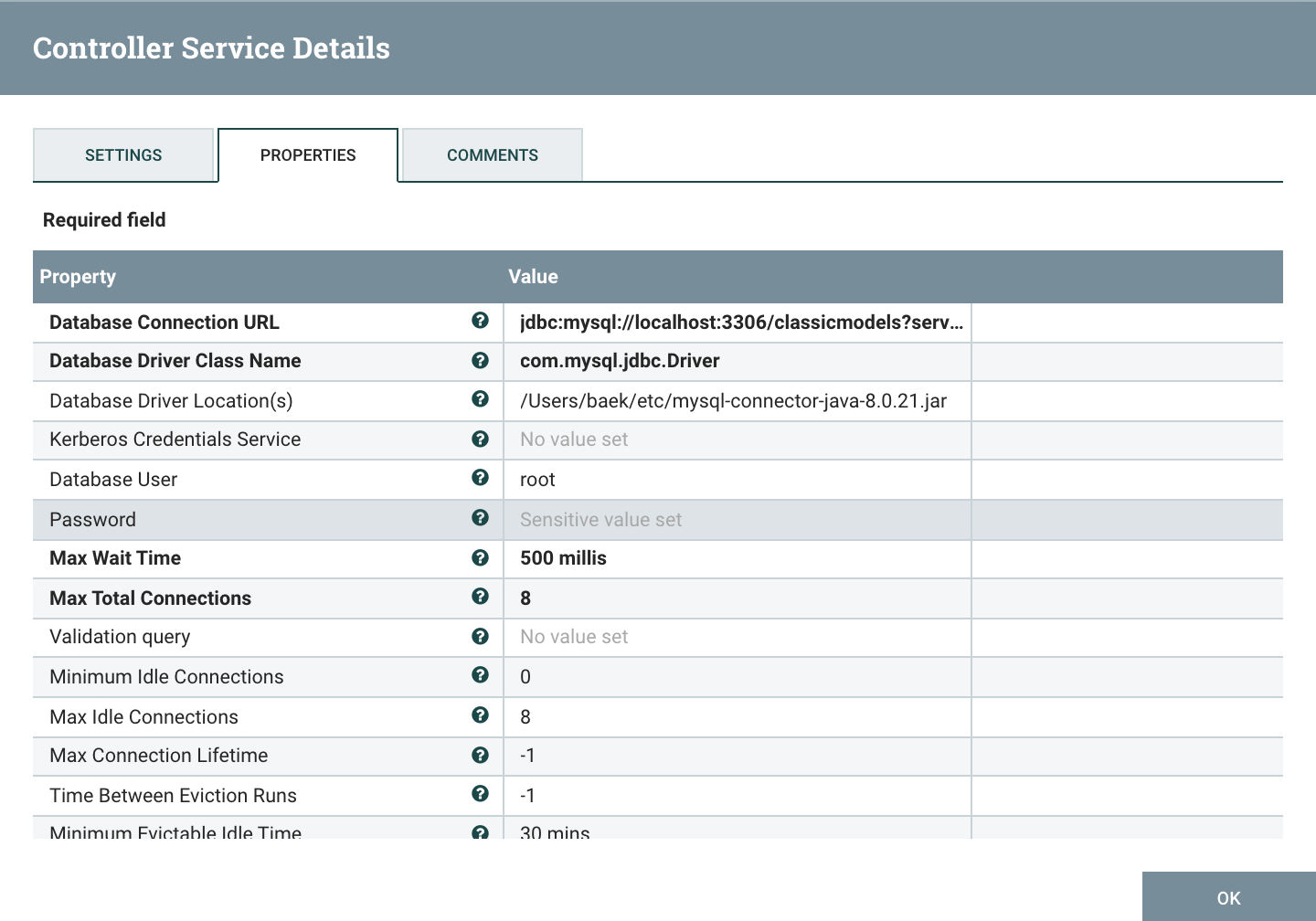
- Database Connection URL : jdbc:mysql://[ip or url]:[포트번호]/[데이터베이스명] ?serverTimezone=UTC(값을 넣지 않으면 timezone error발생)
- Database Driver Class Name : com.mysql.jdbc.Driver
- Database Driver Locations(s) : /connector를 다운받은 위치/connector이름.jar
- Database User : 유저 id
- Password : 패드워드
Connector 다운받기
다운링크에 접속하여 Platform Independent로 설정하여 다운받는다. 압축을 푼 후 jar파일을 해당위치로 옮겨준다.
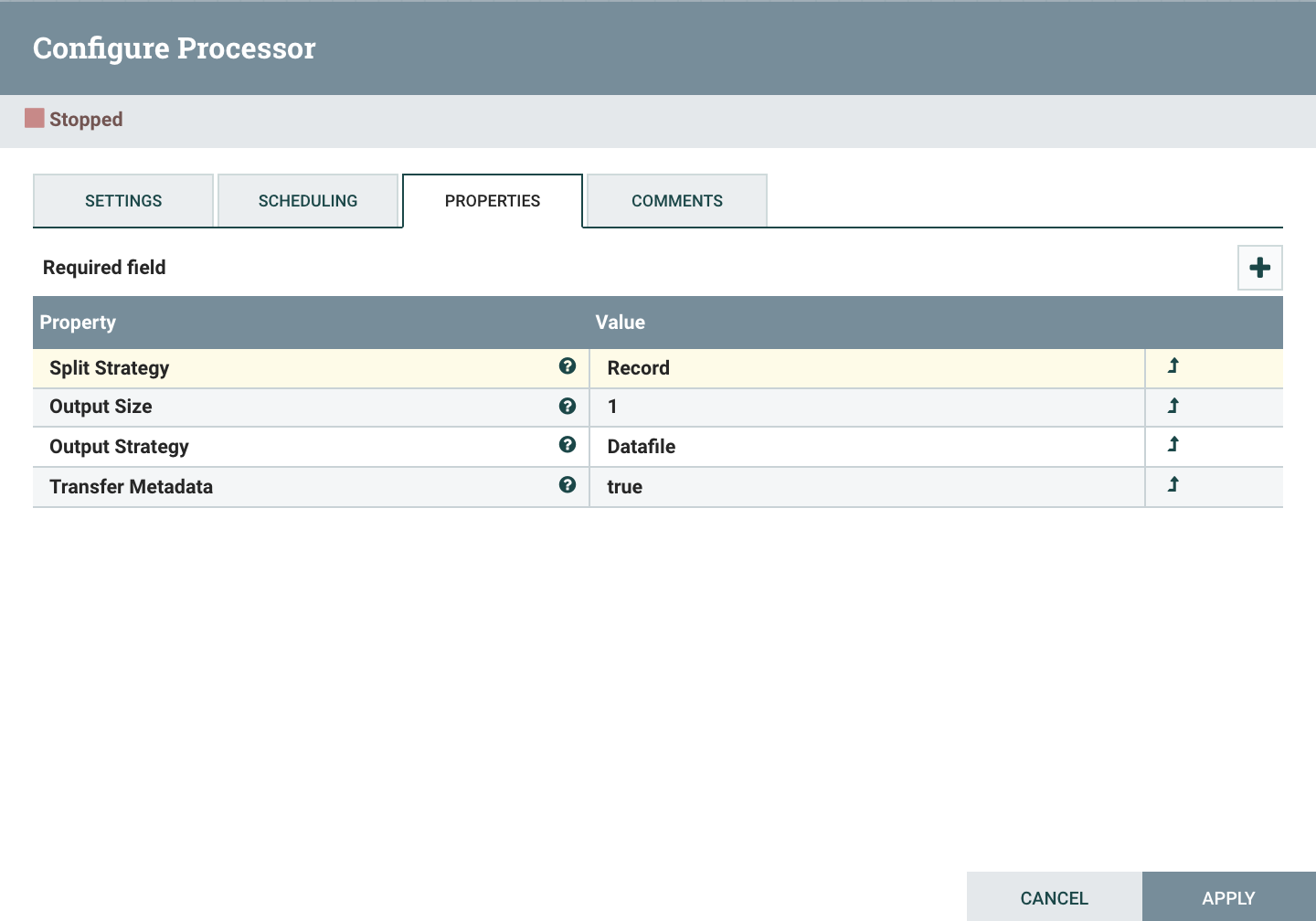
SplitAvro
데이터베이스에서 조회한 결과는 Avro배열로 반환된다. 이를 1개의 레코드로 분할한다.
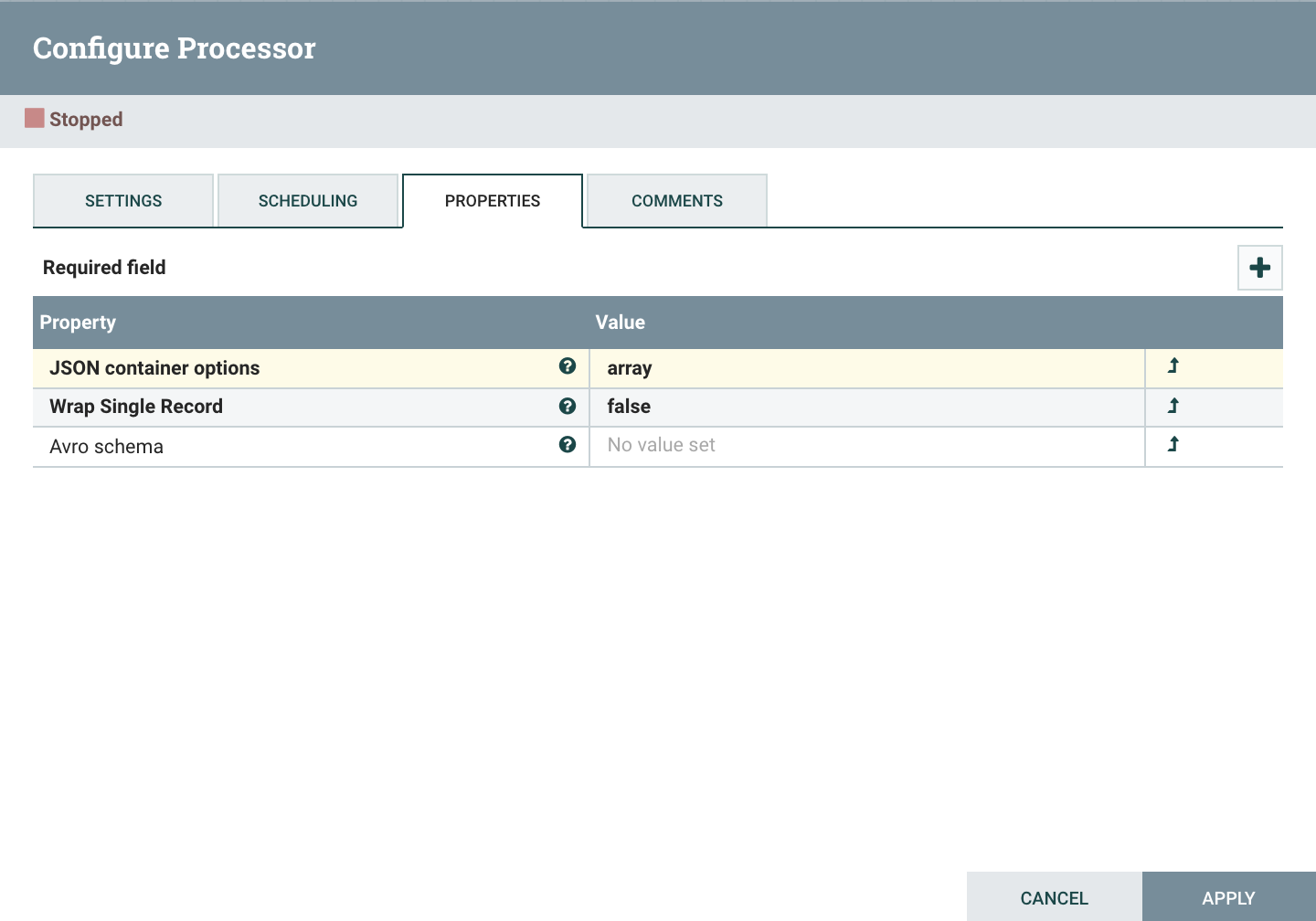
ConvertAvroToJSON
분할한 레코드를 사용하기 편하게 JSON형태로 변환한다.
MergeContent
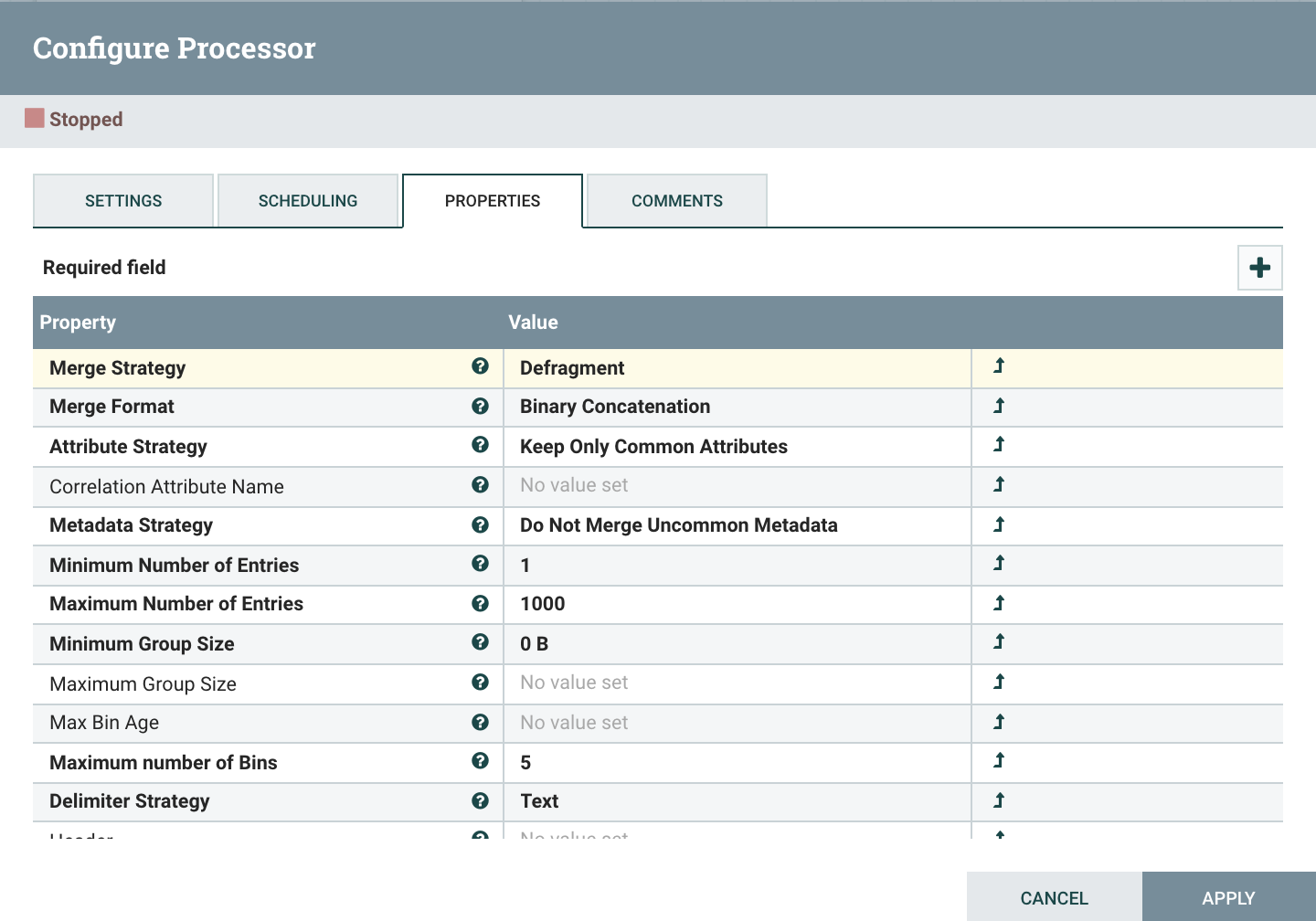
- Merge Strategy : Defragment
- MergeFormat : Binary Concatenation
- Delimiter Strategy : Text
- Demarcator : 병합시 사용되는 구분자. ${literal(‘ ’):unescapeXml()}를 입력하면 한줄씩 Enter된 형태로 값을 얻을 수 있다.
PutFile
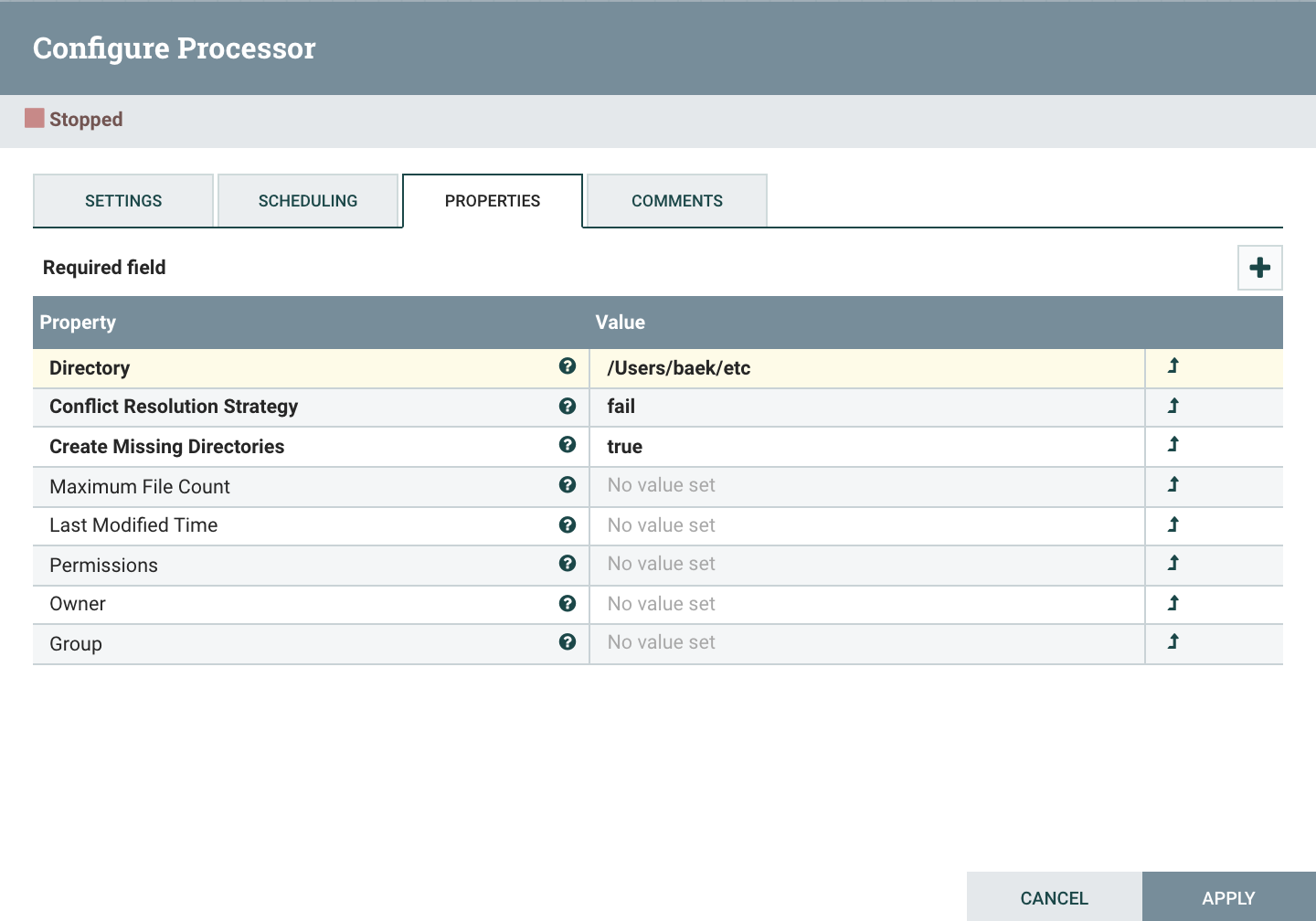
- Directory : 파일을 로컬에 저장할 위치를 지정한다.
결과 확인
아래와 같이 json파일이 한줄씩 저장되어 있는것을 확인할 수 있다.